This tab allows to specify and inspect the input data, to specify how deep into the reduction cascade to go (reduction target), to configure the association preference, and, finally, to create the dataset to reduce.
There are 5 main buttons:
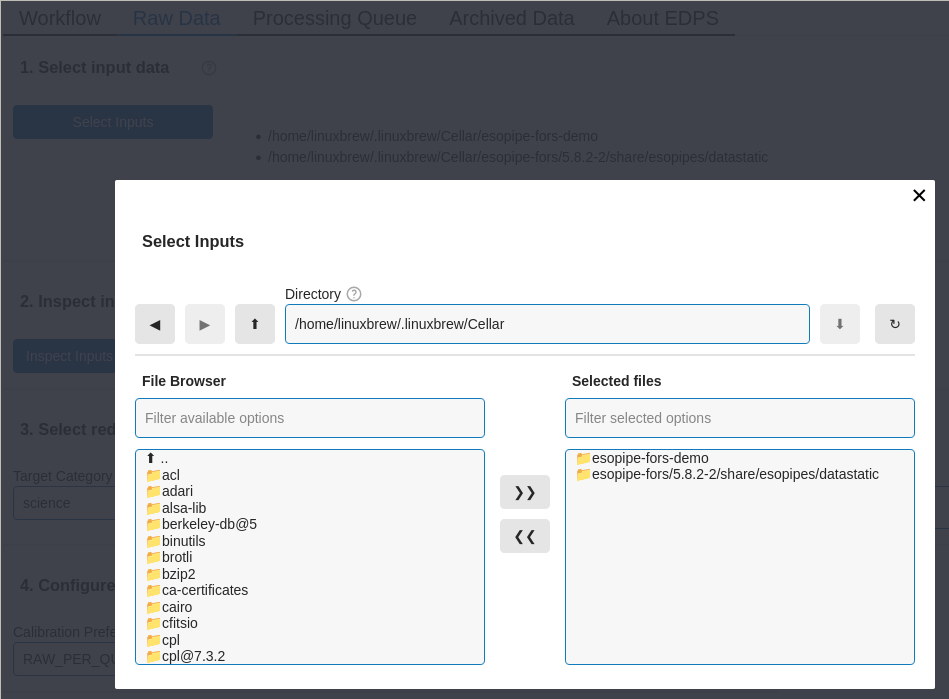
Select the input data. The button “Select Inputs” opens a window that allows to specify the directory where the input data are located.
Inspect the input data. The button “Inspect Inputs” allows to inspect the input files. Press this button and a table with the the list of input files appears. The first part of the table shows the list of the input files, grouped by category. Click on the arrow of each category to show the files within. Buttons on the left side of each file allows to visualize it either with
fvords9(if present in your system).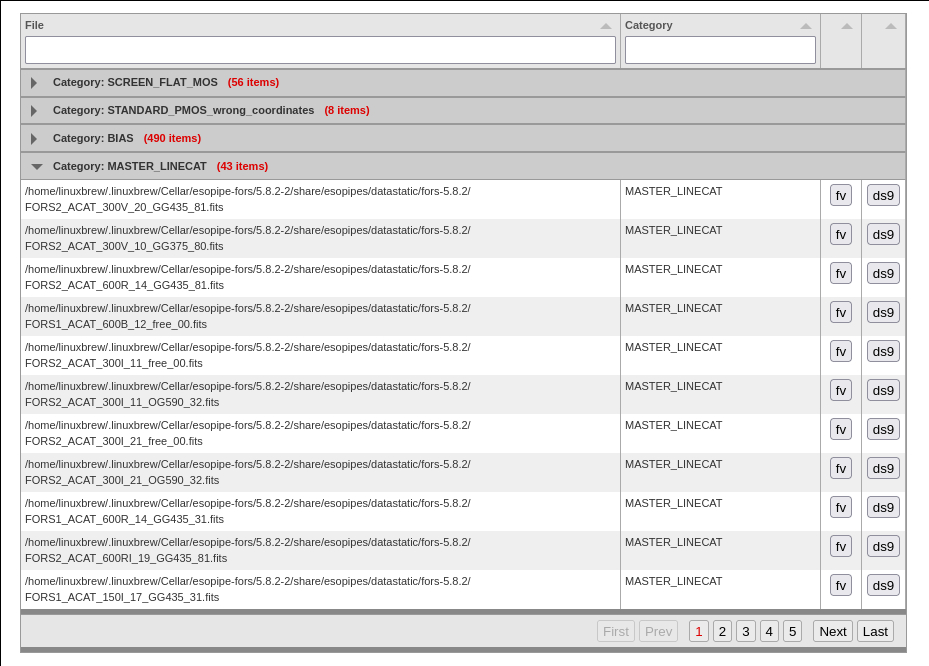
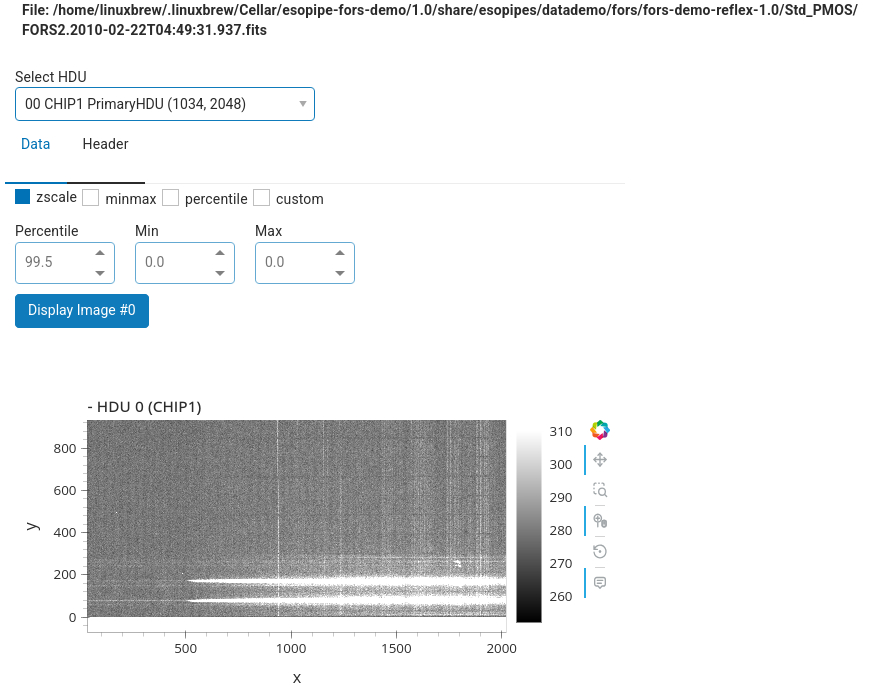
The second part of the table allows to inspect the headers of the various extensions, and also it allows to inspect the data extension with interactive Python tools.
Select reduction target. This window allows to specify the final steps of the reduction cascade, the so-called “target tasks”. The tasks, i.e. the various steps of the reduction flow, are grouped by categories, which can be selected from the drop-down menu “Target Category”.
EDPS processes all the data until the specified target tasks, and triggers all the tasks down in the reduction cascade that are needed to trigger the target task. For example, if the target task is “science”, and the reduction cascade foresees that also the “bias” and “flat_field” tasks are needed to provide the necessary calibrations, then EDPS will process all and only the biases and the flat fields that are needed to reduce the science data. If there are other biases or flat fields that are not needed for the specified science exposure, they are not reduced. On the other hand, if the specified target task is “flat field”, then EDPS will reduce all the flat field exposures, plus all and only the biases that are needed for those flat fields.
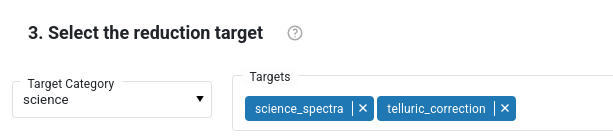
Individual tasks within that category are listed in the “Targets” bar. In the figure below, the “Science” category is shown, that contains the tasks called science_spectra and telluric_correction. The categories and the tasks depends on the loaded workflow. The category “science” is specified by default. The category “all” shows all the tasks in that workflow. Tasks that are not desired, can be removed from the list. The category “qc1calib” triggers all the calibration and instrument monitoring tasks, but it does not process scientific images. Other target categories are specific for Paranal operations, and are not needed for the general user.
Select the workflow parameters This windows allows to specify the so called “workflow parameters”, e.g. parameters that define the strategy of the reduction or, as in case of fors (see figure below), the criteria on how to group files to combine. Workflow parameters can influence which files enter a dataset. Click on the parameter name to visualize a short description. Every workflow has a different list of workflow parameters.
There are several “Parameter sets” that can be selected, e.g. sets whose parameter values are predefined according to specific use cases. By default, the “science” parameter set is loaded, which contains the settings for the most science use cases. This is the recommended parameter set to use or, eventually modify. Other parameters sets are qc0_parameters (for quick inspection at Paranal), idp_parameters (the set used by ESO to populate the science archive), default_parameters (to automatically process calibrations in Chile). Other workflows might contain additional parameters sets, depending on the use case. Note that the parameters shown in this window are only the workflow parameters, e.g. those that can determine the content of the dataset. Other parameters (e.g. recipe parameters) can be configured in the Reduction Queue individually for each dataset (see here).

Create Dataset. This steps creates the datasets to be reduced until the specified reduction target.
The menu “Calibration preference” allows to specify the preferences in associating calibrations (e.g., raw or master calibrations). The various preferences are described here. For regular science reduction the options raw_per_quality_level (default) or master_per_quality_level are recommended.
Press the “Create Dataset” blue button to create the datasets. Datasets, together with all the calibrations needed to process them, are listed in a table. Selected datasets can be sent to the processing queue by pressing the “Submit to Reduction Queue” blue button.
Important notes:
When submitting a dataset, the reduction ‘does not start automatically’. To process a dataset, please, go the the Reduction Queue tab.
You cannot submit to the Reduction queue datasets that are already submitted.
If datasets are already generated, the “Create dataset” button is not active. Because a dataset is defined by the reduction target and the files it contains, to generate new datasets, one has either to specify new input files, change workflow parameters that change the way files are included (e.g., different combination strategy) or change the association preference.
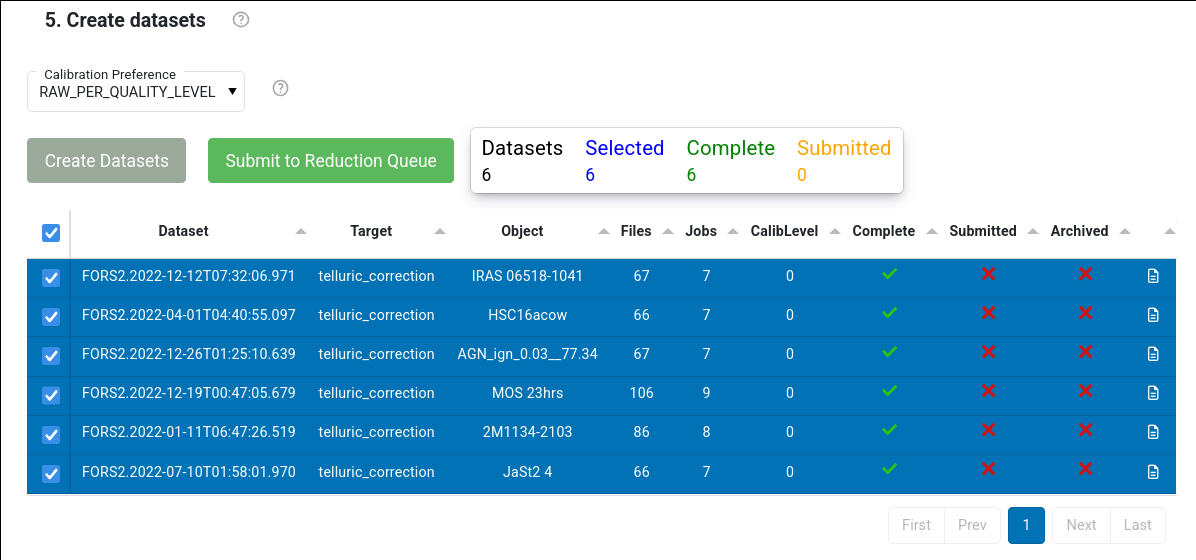
The table shows information about the number of jobs, of files, if a dataset is complete, if it has been submitted to the reduction queue, of whether the final products have been archived. It also indicates the CalibLevel, i.e. a number indicating the quality of the associations for that datasets. If CalibLevel is 0, it means that all the associations are within a “safe” time interval foreseen by the calibration plan of that instruments. Higher numbers indicate associations of lower quality. More information on the levels of associated calibrations can be found here .
The content and the file association within a dataset can be inspected by pressing the button
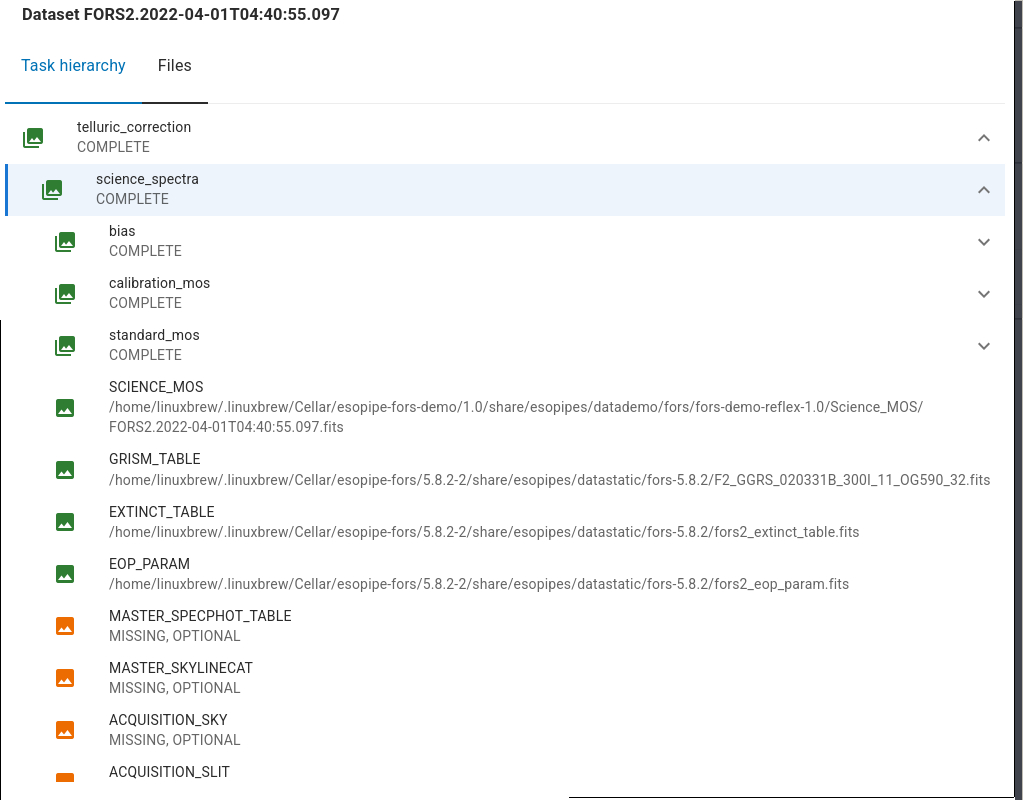
 at the end of each dataset row. This shows the association tree as in the figure below.
Incomplete datasets are marked in red, with the indication of what is missing.
at the end of each dataset row. This shows the association tree as in the figure below.
Incomplete datasets are marked in red, with the indication of what is missing.